A lot of recent studies has shown that psychology has a replicability problem. When you try to replicate a study using the original materials, there is a good chance that you will obtain different results. More often than not, the effect sizes in the replication will be smaller and nonsignificant. As if this was not enough, there is another, even more insidious problem that has not been given much attention. Even when a study replicates successfully, it does not mean that the results actually support the general effect they are supposed to demonstrate. The issue has been raised before; however, it does not seem that people take the warnings seriously. One possible reason is that people do not appreciate how serious the problem is unless they see it demonstrated in practice. Our study, which just came out in Psychological Science, will hopefully help by convincingly demonstrating how using only a fixed set of stimuli might lead to misleading research findings.
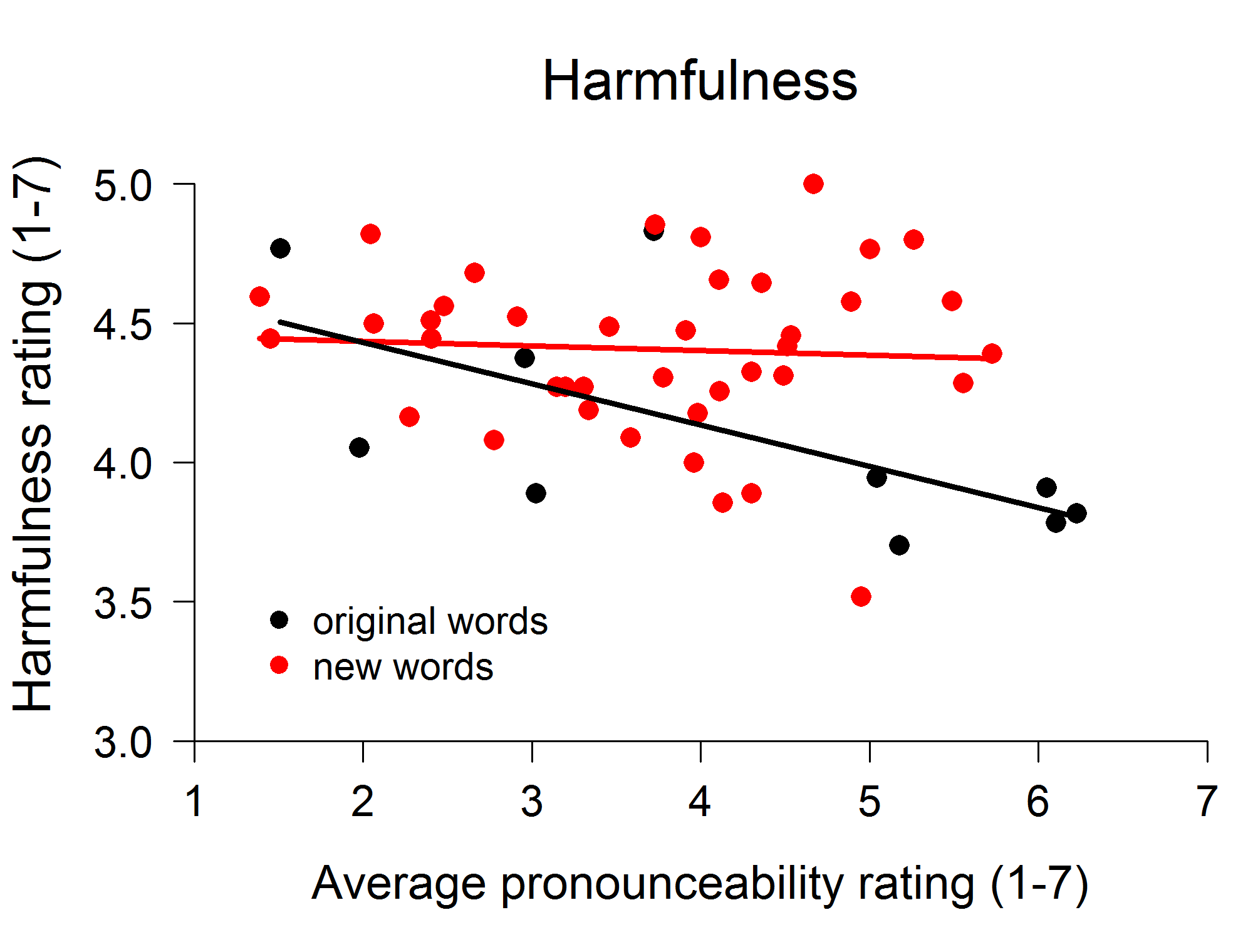
A study by Hyunjin Song and Norbert Schwarz showed that people judge food additives with hard-to-pronounce names as more risky than additives with relatively easy-to-pronounce names. The study was published in 2009 in Psychological Science and has been cited 201 times according to Google Scholar. Song and Schwarz asked their participants to imagine that they are reading names of food additives on a food label and then to evaluate dangerousness of the additives based on their names. In our study, we initially tried to build on their findings and test a possible moderator of the effect; however, after a few hundreds participants and four studies with mixed results, it seemed that the effects we observed strongly depended on the specific stimuli that were used.
While we were able to repeatedly replicate the results of Song and Schwarz, we worried that the problem might affect the original effect as well. We therefore conducted a study in which we used newly created stimuli alongside the stimuli used by Song and Schwarz. The result supported our hunch – we again observed the effect when we analyzed only the original items, but there was no effect for the newly created stimuli.
How is this possible? A simple answer is that we cannot know for sure. The problem might have been caused partly by treating stimuli as a fixed factor. It is possible that the original results would not have been significant if Song and Schwarz had conducted their analysis correctly treating stimuli as a random factor. Psychologists have been warned about this mistake in the past and a couple of times recently as well. When you treat stimuli as a fixed factor, you limit your claim about the existence of the effect only to the particular stimuli used in the experiment. The effect of this analysis choice is clear from the comparison of results of the two possible analyses in the first four studies in our paper. While the analysis using fixed factors yields, for the same materials, enigmatic effects in opposite directions in studies 2 and 3, the effects disappear when stimuli are treated as a random factor:
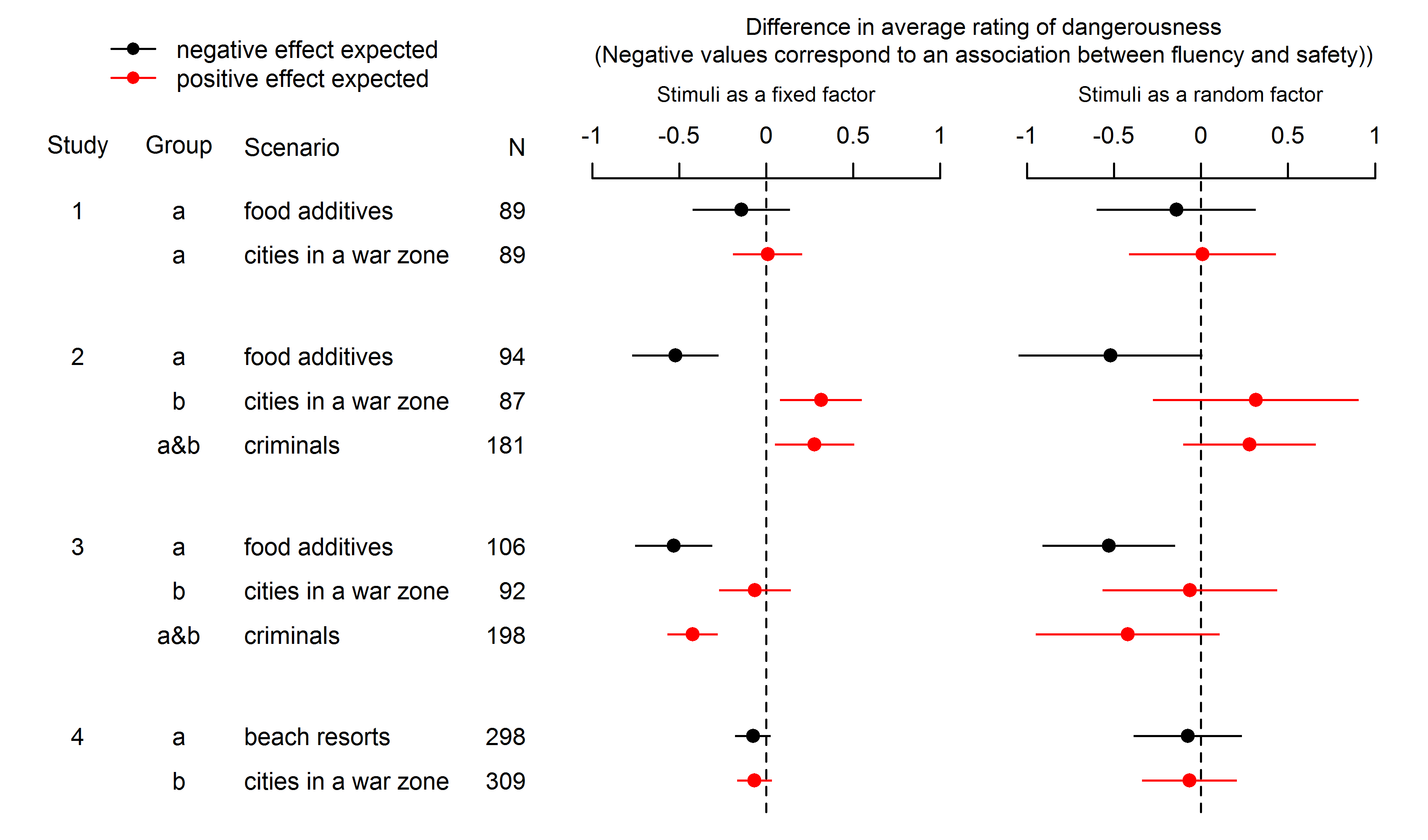
However, simply treating stimuli as a random factor in a statistical analysis does not magically guarantee that significant results are really generalizable. When we analyzed our replications of Song and Schwarz’s effect, the results remained significant even when treating stimuli as a random factor. The problem here is probably deeper and more serious than just not using a correct statistical method: People usually use convenience samples of stimuli in their studies, without any attempt to define the underlying population of stimuli. They may pick the first stimuli that come to mind or stimuli that they believe are likely to produce the desired results. Treating stimuli as a random factor helps with generalizability only if the used stimuli are representative of the population of stimuli that are of interest. However, it cannot by itself remedy the cases where bias crept in during the stimuli-selection procedure. We cannot be sure why the effect of pronounceability on perceived risk exists only for the original stimuli used by Song and Schwarz. It is entirely possible that they just had (bad) luck and selected hard-to-pronounce names that were somehow related to danger purely by accident.
Nevertheless, the moral of the story is clear – it is important to have a systematic procedure for generating stimuli and to treat the stimuli as a random factor in analysis. Otherwise, we might end up with highly replicable studies that won’t give us any generalizable knowledge about the world.
This post was written together with Marek Vranka.